
AgTech is focusing on all the wrong things
I didn’t become a farmer until I was 37. And up until that point, I have to admit I wasn’t even very interested in it. In the early parts of my career, I thought I wanted to reach the top of the corporate ladder. I didn’t reach the top, and now I don’t want to anymore, but I learned a few things along the way – a few things that make me see agriculture and AgTech a little differently than others, it seems.
For many years I worked on the digitalization of the oil & gas, renewable energy, and shipping industries. From around 2010, we took baby steps in big data analytics, machine learning, the internet of things, data platforms, and the API economy. As it goes with new technology hype cycles, not everything was as easy to implement as it seemed in the idea stage. And now that I observe these same topics increase in popularity in the AgTech space, I can’t escape the deja vu feeling.
As the graph illustrates, most other industries have reached a higher level of digitalization, and naturally, agriculture takes inspiration from this. The inspiration is misguided, though.
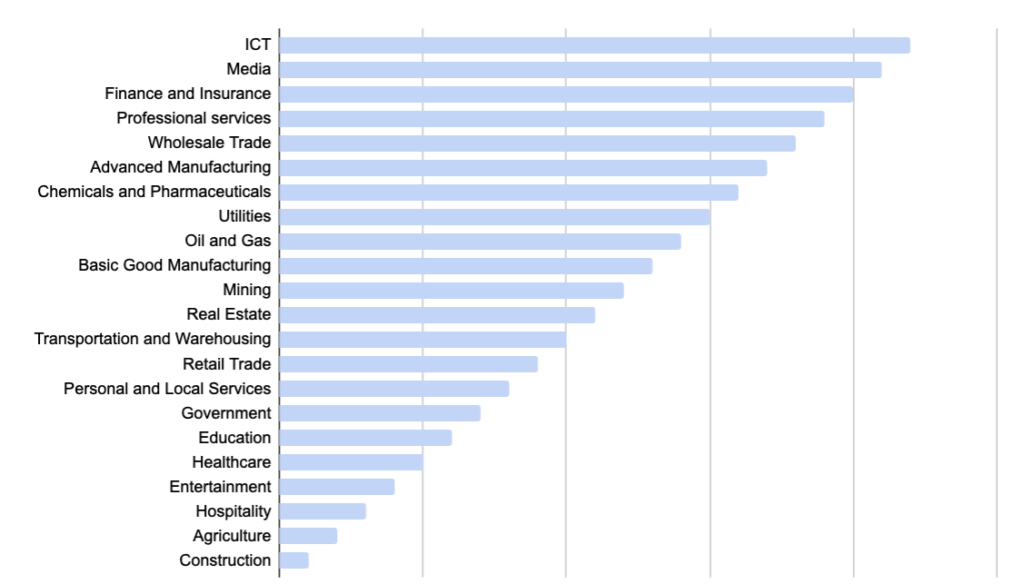
Digitalization can mean many different things, but most of what I see happening in AgTech now is inherited from other industrial sectors – it’s about sensors, satellites, drones, and cameras generating data streams that can be analyzed and used for decision-making. It’s not so much about clever new business models yet, which only means the AgTech space is not yet very mature.
So we’re at the same stage as when I started working with the same topics in those other industries. Except, back then, at least the objective was pretty straightforward: we wanted to predict and fix problems before they occurred, thereby avoiding downtime.
Imagine a large drillship, it drills holes thousands of meters below the seafloor, so oil and gas can be produced. It costs about 250 000 dollars a day, and any downtime directly means extra cost and delays. The value of predicting a problem early is extremely large.
To be very concrete, “digitalization” applied to this drillship meant the following: there are approximately 10 000 sensors onboard, vibration, temperature, and pressure being prominent sensor types. These sensors constitute the main data source for predicting failures, and analyzing them requires 5 steps:
In other words, it’s hard to realize the promises made – which is why it is not materializing anywhere near the expected speed.
Still, AgTech takes inspiration from these other industrial sectors and seems to try and do the same things. In many ways, it’s much easier to do these 5 steps for a tractor or other agricultural machinery than for the said drillship. They don’t have different vendors, the correlation matrix is much smaller, failure modes are fewer, and equipment-side computation is a smaller endeavor.
I know John Deere likes to portray their tractors as large machines. But it’s important to observe that they are logically small. By that, I mean that most farmers have several machines doing the same job, and their choice of size and number of machines is a result of optimizing job capacity, job flexibility, and redundancy. If one machine has downtime, this rarely translates directly to reduced farm productivity.
In comparison, two small drillships can never do the same job as the large ones.
I am a farmer. This means my main concern lies with the productivity of my fields – not on whether my tractor works. For example, I want to know why a field has scattered flowering and how to fix it so I can produce more apples. The vibration readings and status of the bearings on my tractors will never directly impact this.

This is when AgTech suggests we apply the same logic to the orchard itself. Let’s just install more sensors, take more pictures and analyze it. This raises another concern. How will we generate enough data to connect failure modes with data patterns? How to get enough experience data to learn from?
Let’s do another example from the drillship. There are many valves onboard, whose job it is to let fluid through or not. They might open and close every second, every minute, or every day – and every time it completes a full operational cycle that can be learnt from. For simplicity, a specific valve opens and closes 1000 times per year. This valve has a hundred sister valves installed elsewhere. In total, this generates experience data from 100 000 operational cycles per year. This is the type of data set we need to create the correlation matrix and connect data patterns to failure modes.
My orchard, as pictured above, generates one operational cycle per year, so only after 100 000 years will we have the same data set for the example valve.
Clearly, this is a misguided approach. The seasonality of farming is a showstopper to the digitalization attempts other industries are betting on.
I am not saying there is no role for all these new technologies in agriculture, but the implementation order must be different. The technology providers must direct their efforts more toward what the farmers need to fix. And the farmers need to engage much more in the dialogue to get usable solutions.
I want to see a future for agriculture where technology helps automate the farming processes and support decision-making, but I don’t see that happening through machine learning of big data streams and remote sensing. I think we need to build technology that brings the industry’s stakeholders closer together and facilitates learning across larger parts of the industry. By bringing together farming work processes, knowledge, observations, and data points, technology can, over time, learn how we do it and then guide us. It’s parallel to how Tesla developed the autopilot. They let the technology observe how humans drive, then it tries to help, and only at the end of that comes full autonomy. And we are not there yet, either for driving or farming.
By the way, we have written a 7-part blog series on what we think Agtech and precision agriculture should focus on: